Spectrometer¶
Spectrometers may be used to measure the spectral response of a system. A probe is pointed at the light source and the sample feeds through to the internal optical bench, which typically comprises routing mirrors, a prism or diffraction grating to separate the sample into its constituent wavelength components, and a sensor.

Our JAZ spectrometer has a 16-bit CCD sensor with 2048 pixels and reports wavelengths from 330-1030 nm. The raw spectrum is reported in counts, a unit of measurement relating to the number of photons hitting the sensor during the integration period.
Obtaining measurements¶
python-seabreeze¶
A good alternative to OceanOptics software is the python-seabreeze library, which enables connection to Ocean Optics spectrometers from Python and provides good functionality.
pip install seabreeze
Here’s a nice clean way to obtain and visualise a sample using seabreeze.
[4]:
import matplotlib.pyplot as plt
import seaborn as sns
from seabreeze import spectrometers
sns.set_style('ticks')
sns.set_context('notebook')
try:
# Connect to spectrometer
oo = spectrometers.Spectrometer.from_serial_number('JAZA1505')
# Set integration time
oo.integration_time_micros(1e5) # 1 s
# Get reported wavelengths
wls = oo.wavelengths()
# Obtain pixel intensities
counts = oo.intensities(
correct_dark_counts=True,
correct_nonlinearity=True
)
# Visualise
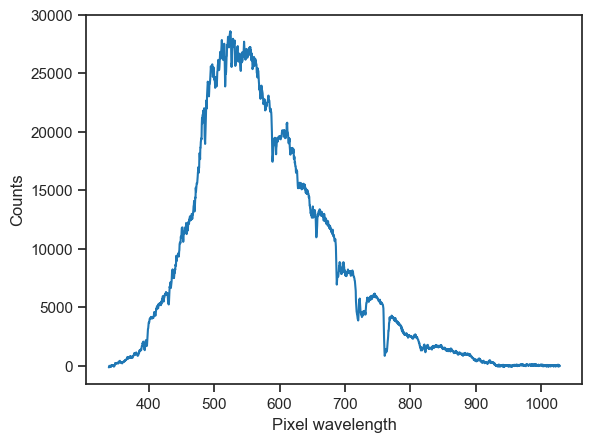
plt.plot(wls, counts)
plt.xlabel('Pixel wavelength')
plt.ylabel('Counts')
except Exception as e:
raise e
finally:
oo.close()
pyplr.oceanops.OceanOptics¶
This is my own extension to the seabreeze.spectrometer.Spectrometers class. It includes a sampling method with additional features like automatically adapting the integration time of a measurement to hit 80-90% maximum pixel saturation (where the sensor is most linear), averageing a number of scans, and boxcar smoothing.
pip install pyplr
It works in the same way and has all the same functionality, but there is a new .sample(...) method with some extra options.
[6]:
from pyplr import oceanops
try:
# Connect to spectrometer
oo = oceanops.OceanOptics.from_serial_number('JAZA1505')
# Obtain sample
counts, info = oo.sample(
correct_dark_counts=True,
correct_nonlinearity=True,
integration_time=None, # Optimize integration time
scans_to_average=3, # Average of three scans
boxcar_width=3, # Boxcar smoothing
sample_id='daylight_spectrum'
)
# Visualise
counts.plot(xlabel='Pixel wavelength', ylabel='Counts')
except KeyboardInterrupt:
print('> Measurement terminated by user')
finally:
oo.close()
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.001 seconds
> Maximum reported value: 232
> Integration time: 0.239306 seconds
> Maximum reported value: 34789
> Integration time: 0.383174 seconds
> Maximum reported value: 53368
> Computing average of 3 scans
> Applying boxcar average (boxcar_width = 3)
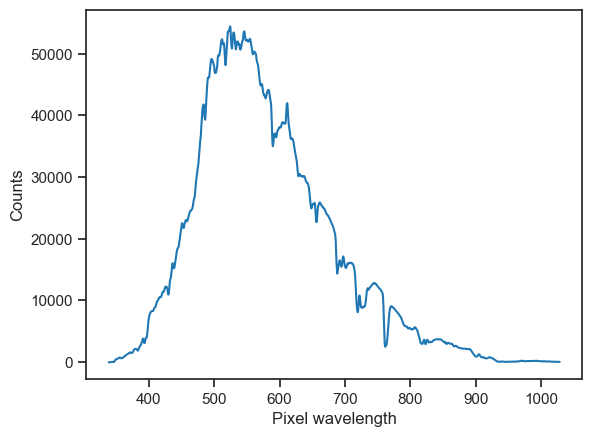
Instead of returning np.array, the .sample(...) method returns pd.Series and a Python dictionary with information about the sample.
[7]:
counts
[7]:
Wavelength
339.117800 -53.088918
339.496622 -53.088918
339.875414 -53.088918
340.254178 -53.088918
340.632913 -40.432069
...
1027.022982 31.690945
1027.304901 33.462733
1027.586755 33.462733
1027.868542 33.462733
1028.150263 33.462733
Name: Counts, Length: 2048, dtype: float64
[8]:
info
[8]:
{'board_temp': 'NA',
'micro_temp': 'NA',
'integration_time': 399950,
'scans_averaged': 3,
'boxcar_width': 3,
'max_reported': 54440.926608466776,
'upper_bound': 58981.5,
'lower_bound': 52428.0,
'model': 'JAZ',
'serial': 'JAZA1505',
'obtained': '2022-10-21 16:21:39.521732',
'sample_id': 'daylight_spectrum'}
Also, if you don’t specify an integration time, it will be adjusted until the maximum reported value is within 80-90% of pixel resolution, where linearity is best (as above).
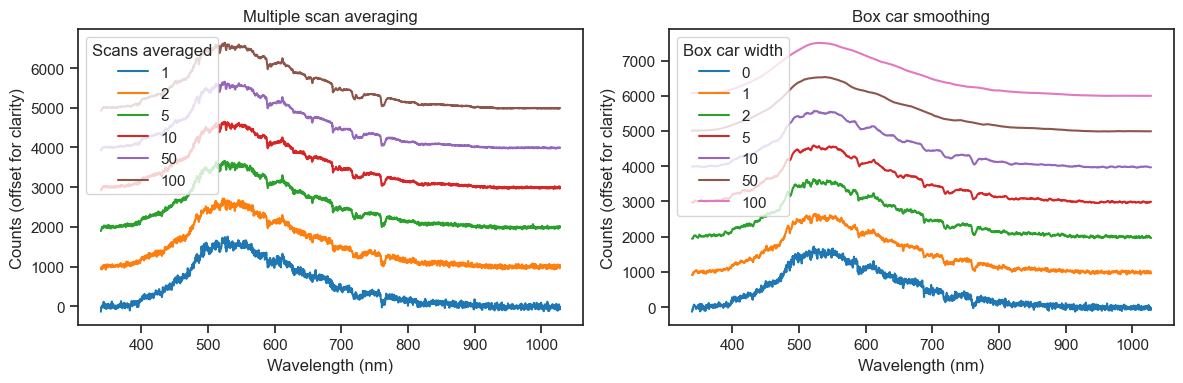
Signal-to-noise ratio may also be improved with scan averaging and boxcar smoothing, but be warned! The former increases overall sampling time and the latter comes at the expense of optical resolution and may wash out spectral features if a high value is used. A good rule of thumb is to use low values (e.g., 1-3). A better rule of thumb is to save each raw measurement and apply these steps later.
[9]:
try:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
oo = oceanops.OceanOptics.from_serial_number('JAZA1505')
for i, scans_to_average in enumerate([1, 2, 5, 10, 50, 100]):
counts, info = oo.sample(
correct_dark_counts=True,
correct_nonlinearity=True,
integration_time=1e4,
scans_to_average=scans_to_average
)
ax1.plot(counts+(i*1000), label=scans_to_average)
ax1.set_title('Multiple scan averaging')
ax1.legend(title='Scans averaged')
for i, boxcar_width in enumerate([0, 1, 2, 5, 10, 50, 100]):
counts, info = oo.sample(
correct_dark_counts=True,
correct_nonlinearity=True,
integration_time=1e4,
boxcar_width=boxcar_width
)
ax2.plot(counts+(i*1000), label=boxcar_width)
ax2.set_title('Box car smoothing')
ax2.legend(title='Box car width')
for ax in (ax1, ax2):
ax.set_xlabel('Wavelength (nm)')
ax.set_ylabel('Counts (offset for clarity)')
plt.tight_layout()
except KeyboardInterrupt:
print('> Measurement terminated by user')
finally:
oo.close()
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1757
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1724
> Computing average of 2 scans
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1790
> Computing average of 5 scans
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1699
> Computing average of 10 scans
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1691
> Computing average of 50 scans
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1685
> Computing average of 100 scans
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1718
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1704
> Applying boxcar average (boxcar_width = 1)
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1697
> Applying boxcar average (boxcar_width = 2)
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1742
> Applying boxcar average (boxcar_width = 5)
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1683
> Applying boxcar average (boxcar_width = 10)
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1713
> Applying boxcar average (boxcar_width = 50)
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.01 seconds
> Maximum reported value: 1705
> Applying boxcar average (boxcar_width = 100)
I like my Seabreeze extension. It’s very useful for automating measurements (e.g., when measuring the spectral response of a multi-primary system).
Wavelength calibration¶
The pixels on the spectrometer CCD sensor are aligned to different wavelengths.
According to Ocean Optics, the relationship between pixel and wavelength is described by a third-order polynomial:
\begin{equation} \lambda_p = I + C_1 p + C_2 p^2 + C_3 p^3 \end{equation}
Where:
\(\lambda\) = wavelength of pixel \(p\)
\(I\) = wavelength of pixel 0
\(C1\) = first coefficient (nm/pixel)
\(C2\) = second coefficient (nm/pixel\(^2\))
\(C3\) = third coefficient (nm/pixel\(^3\))
The JAZ stores wavelength coefficients from when it was last calibrated, but wavelength calibrations are liable to drift over time due to various factors (e.g., mechanical shock, environmental conditions).
The ground truth for wavelength calibration is dervied from sampling a light source that produces spectral lines, so we borrowed a Philips argon lamp from our local physics department.

Measurement of the lamp produced a spectrum with lots of lines. I consulted the NIST atomic spectra database to find the known positions of the lines.
[12]:
import numpy as np
import pandas as pd
# Load sample and spectral lines
ar_spd = pd.read_csv('../../data/jazcal/jaz_Ar_spd.csv', index_col='wl')
ar_lines = pd.read_csv('../../data/jazcal/NIST_Ar_1_lines_300_1000.csv')
# Plot spd and line positions
fig, ax = plt.subplots(figsize=(12, 3))
ar_spd.pwr.plot(ax=ax, lw=.5, label='Argon lamp SPD')
ax.vlines(ar_lines['wl'], -3500, -1750, color='purple', lw=.5, label='Ar I line positions')
ax.set(xlabel='Pixel wavelength (nm)',
ylabel='Counts')
ax.legend();
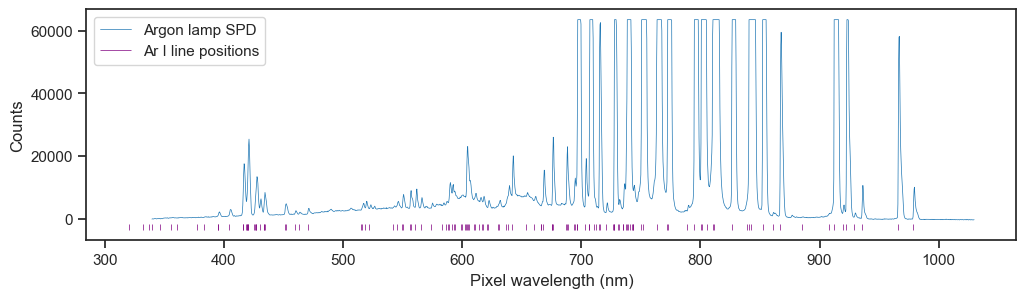
Many of the lines were not resolved by the spectrometer, presumably due to undersaturation or pixel resolution limitations, but most tallied up with visible peaks. I used a peak-finding algorithm to try and find the corresponding peaks in the spectrum, based on certain criteria.
[13]:
from scipy import signal
# Find peaks
peak_idxs = signal.find_peaks(
ar_spd['pwr'],
height=1800,
prominence=300,
threshold=30,
distance=10)[0]
peaks = ar_spd.loc[ar_spd.pxl.isin(peak_idxs)].reset_index()
ax.vlines(peaks['wl'], -1750, peaks['pwr'], lw=.5)
ax.set_xlim((380, 780))
ax.set_ylim((-3000, 30000))
ax.legend()
fig
[13]:
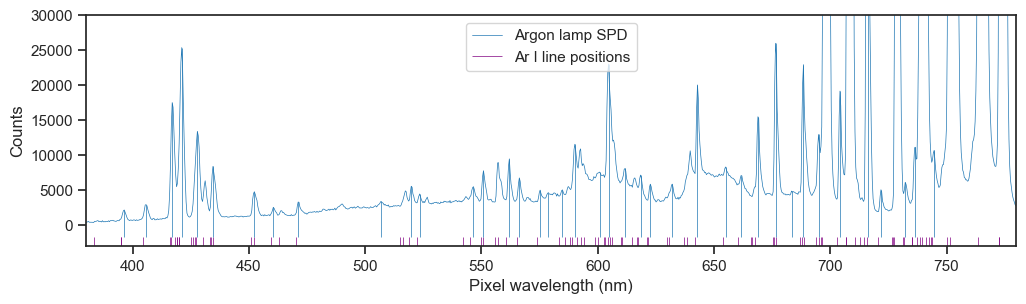
This showed a general pattern of rightward drift of about 1 nm, but the line pairing was not obvious so I zoomed in on a pdf plot and manually paired the detected peaks with the nearest line to the left, if there was one, dropping it otherwise. This led to 44 lines accross the full range of reported wavelengths.
[14]:
# True line positions for selected peaks
true_wls = [
394.8979, 404.4418, 415.859, 419.8317, 426.6286, 433.3561,
451.0733, 459.6097, 470.2316, 518.7746, 522.1271, 545.1652,
549.5874, 560.6733, 565.0704, 573.952, 583.4263, 588.8584,
599.8999, 603.2127, 610.5635, 617.3096, 621.5938, 630.7657,
641.6307, 653.8112, 660.4853, 667.7282, 675.2834, 687.1289,
693.7664, 703.0251, 714.7042, 720.698, 731.1716, 735.3293,
743.6297, 789.1075, 860.5776, 866.7944, 919.4638, 935.422,
965.7786, 978.4503
]
# Remove suspect peaks without a true-line companion
drop_px = [448, 648, 947]
peaks = peaks.loc[~peaks.pxl.isin(drop_px)]
peaks['true_wl'] = true_wls
Now, to calculate the wavelength coefficients and predict the new values.
[15]:
# Third order polynomial
poly = np.polyfit(peaks['pxl'], peaks['true_wl'], deg=3)
print('> The wavelength coefficients are:\n')
print(*poly[::-1], sep='\n')
calibrated_wls = np.polyval(poly, ar_spd.pxl)
> The wavelength coefficients are:
338.5374924539017
0.3802367113739599
-1.5959354792685768e-05
-2.507246200675931e-09
These coefficients can be updated in the spectrometer using Ocean Optics software, or the new wavelengths can be applied at a later stage of processing.
Here’s the visible portion of the original spectrum plotted against the old and new wavelengths. Note that the true lines match better with the peaks when they are plotted against the calibrated wavelengths.
[16]:
fig, ax = plt.subplots(1, 1, figsize=(12, 3))
ax.plot(ar_spd.index, ar_spd.pwr, lw=1, label='Old Wavelengths')
ax.plot(calibrated_wls, ar_spd.pwr, lw=1, label='Calibrated Wavelengths')
ax.vlines(true_wls, 0, 60000, color='purple', lw=.4, label='Ar I line positions')
ax.set(xlim=(380, 780),
ylim=(0, 30000),
xlabel='Wavelength (nm)',
ylabel='Counts')
ax.legend(loc='upper left');
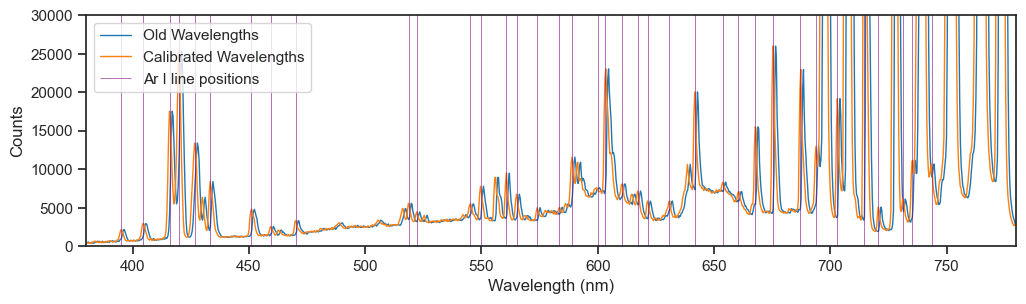
In the end it was a lot of effort for a small correction, but worth it!
Absolute irradiance calibration¶
Absolute irradiance calibration allows for measurements to be reported in energy units, such as \(\mu W/cm^2/nm\), which can be preferable to counts-based measures. This is achieved by taking a reference measurement of a radiometrically calibrated light source with known power output and then working out, for each pixel, how many microjoules a count represents (i.e., \(\mu J/count\) ratio).
According to Ocean Optics, with the \(\mu J/count\) ratio for each pixel, one can convert to energy units using this forumla:
\begin{equation} I_p = (S_p - D_p) * C_p / (T * A * dL_p) \end{equation}
Where:
\(C_p\) = calibration file, in \(\mu J/count\) (specific to the sampling optic)
\(S_p\) = sample spectrum in count units
\(D_p\) = dark spectrum in count units (i.e., the electrical noise floor)
\(T\) = integration time in seconds
\(A\) = collection area in cm\(^2\)
\(dL_p\) = wavelength spread (how many nanometers each pixel represents)
Our NIST-traceable HL-2000-CAL light source is suitable for absolute irradiance calculation. It has a tungsten-halogen bulb with a color temperature of 3100 kelvin, and it came with calibration files expressing its known power output at certain wavelengths in \(\mu W/cm^2/nm\), when measured with either a fibre optic probe or cosine corrector (the sampling optic affects the measured power).
It is relatively easy to perform an absolute irradiance calibration with the Ocean View software, which is available for a 30-day free trial.
Turn the light source on and wait for it to reach thermal equilibrium (~15 mins) and then select the Absolute Irradiance Calibration option. The software guides you through the process of taking a reference measurement, a dark measurement to compensate for electrical noise in the CCD, uploading the relevant lamp calibration file, and obtaining the \(\mu J/count\) pixel calibration file.

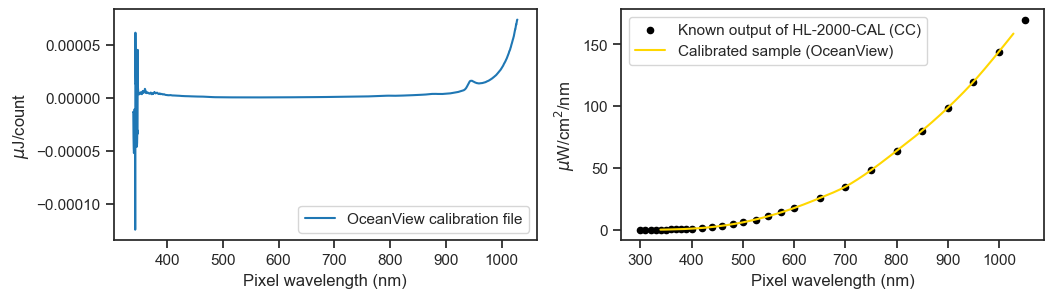
The calibration output looks like this.
[30]:
import pandas as pd
# Load the HL-2000-CAL lamp calibration data for cosine corrector
lamp_file = pd.read_table('../../data/jazcal/030410313_CC.LMP', header=None)
lamp_file.columns = ['Wavelength', 'uJ/cm2']
lamp_file = lamp_file.squeeze()
# Load the Ocean View calibration output
ocean_view_cal = pd.read_table('../../data/jazcal/oceanview_jaz_cc_OOIIrrad.cal', skiprows=8).squeeze()
lamp_preview = pd.read_table('../../data/jazcal/oceanview_jaz_cc_LampIntensityPreview.txt', skiprows=8)
lamp_preview.columns = [s.strip(' ') for s in lamp_preview.columns]
lamp_preview = lamp_preview.set_index('Wavelength').squeeze()
# Visualise
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 3))
ocean_view_cal.plot(ax=ax1, ylabel='$\mu$J/count', label='OceanView calibration file')
lamp_file.plot(ax=ax2, x='Wavelength', y='uJ/cm2', kind='scatter', color='k', label='Known output of HL-2000-CAL (CC)')
lamp_preview.plot(ax=ax2, c='gold', ylabel='$\mu$W/cm$^2$/nm', label='Calibrated sample (OceanView)');
for ax in [ax1, ax2]:
ax.set(xlabel='Pixel wavelength (nm)')
ax.legend()
Here’s how to perform the irradiance calibration without using OceanView.
[82]:
import numpy as np
from scipy import interpolate
import matplotlib.pyplot as plt
from pyplr.oceanops import OceanOptics
# Load the HL-2000-CAL lamp calibration data for fibre optic probe
lamp_file = pd.read_table('../../data/jazcal/030410313_CC.LMP', header=None)
lamp_file.columns = ['Wavelength', 'uJ/cm2']
lamp_file = lamp_file.squeeze()
try:
# Connect to JAZ
oo = OceanOptics.from_serial_number('JAZA1505')
# Perform reference measurement
input('Hit enter to obtain reference measurement:')
reference_counts, reference_info = oo.sample(
correct_nonlinearity = True,
correct_dark_counts = False,
scans_to_average=3,
boxcar_width=2
)
reference_counts.plot(figsize=(4, 2), title='Reference')
plt.show()
# Perform dark measurement
input('Now block all light and hit enter to obtain dark counts:')
dark_counts, dark_info = oo.sample(
correct_nonlinearity = True,
correct_dark_counts = False,
integration_time = reference_info['integration_time'],
scans_to_average=3,
boxcar_width=2
)
dark_counts.plot(figsize=(4, 2), title='Dark counts')
plt.show()
# Resample lamp file to pixel wavelengths
interp_func = interpolate.interp1d(lamp_file['Wavelength'], lamp_file['uJ/cm2'])
wavelengths = reference_counts.index
resampled_lamp_data = interp_func(wavelengths)
# Calculate scaling parameters
integration_time = reference_info['integration_time'] / 1e6 # Microseconds to seconds
fibre_diameter = 3900 / 1e4 # Microns to cm
collection_area = np.pi * (fibre_diameter/2) ** 2 # cm2
wavelength_spread = np.hstack( # How many nanometers each pixel represents
[(wavelengths[1] - wavelengths[0]),
(wavelengths[2:] - wavelengths[:-2]) / 2,
(wavelengths[-1] - wavelengths[-2])
]
)
# Make the calibration file. To do this we need to adapt the
# formula slightly, dividing the resampled lamp data by the
# reference measurement (instead of multiplying the reference
# measurement by the calibration file).
calibration_file = (
resampled_lamp_data
/ ((reference_counts - dark_counts)
/ (integration_time
* collection_area
* wavelength_spread)
)
)
except KeyboardInterrupt:
print('> Calibration terminated by user')
except Exception as e:
print('> Something else went wrong')
raise e
finally:
oo.close()
print('> Closing connection to spectrometer')
Hit enter to obtain reference measurement:
> Obtaining sample...
> Correcting for dark counts: False
> Correcting for nonlinearity: True
> Integration time: 0.001 seconds
> Maximum reported value: 3406
> Integration time: 0.016354 seconds
> Maximum reported value: 29330
> Integration time: 0.031061 seconds
> Maximum reported value: 53673
> Computing average of 3 scans
> Applying boxcar average (boxcar_width = 2)
Now block all light and hit enter to obtain dark counts:
> Obtaining sample...
> Correcting for dark counts: False
> Correcting for nonlinearity: True
> Integration time: 0.032236 seconds
> Maximum reported value: 1795
> Computing average of 3 scans
> Applying boxcar average (boxcar_width = 2)
> Closing connection to spectrometer
Let’s compare the new calibration with the one from Ocean View and focus on the visible wavelengths.
[83]:
from mpl_toolkits.axes_grid1.inset_locator import (
mark_inset,
inset_axes
)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4), tight_layout=True)
# Plot OceanView calibration
ocean_view_cal.plot(ax=ax1, title='OceanView calibration', legend=False)
axins1 = inset_axes(ax1, '40%', '40%', loc='lower center')
ocean_view_cal.plot(ax=axins1, legend=False)
# Plot this calibration
calibration_file.plot(ax=ax2, title='This calibration')
axins2 = inset_axes(ax2, '40%', '40%', loc='lower center')
calibration_file.plot(ax=axins2, legend=False, xlabel='')
for axins in [axins1, axins2]:
axins.set_xlim(380, 780)
axins.set_ylim((0., .000005))
axins.set_xticklabels([])
axins.minorticks_on()
axins.tick_params(which='both', bottom=False, right=True)
axins.grid(True, 'both')
yaxlims = (-.00015, .0001)
for ax, axins in zip([ax1, ax2], [axins1, axins2]):
ax.set_ylim(yaxlims)
ax.set_ylabel('$\mu$J/count')
ax.set_xlabel('Pixel wavelength')
ax.indicate_inset_zoom(
axins,
edgecolor="black",
transform=fig.transFigure
)
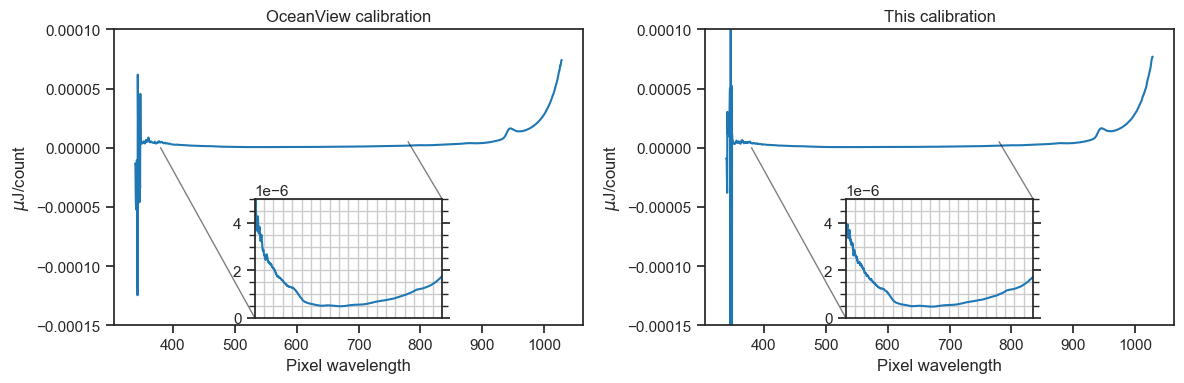
The insets show, according to each calibration file, the \(\mu J/count\) ratio for all pixels that represent visible wavelengths. It’s the same shape! The slight difference in magnitude could be related to adjustments to the sampling optic between calibrations (i.e., I swapped the fiber at one point to calibrate with the long fiber optic cable). Also, the set screw on the light source was jammed for a while, which stopped the probe being inserted to maximum depth.
The final test… apply the original formula to the reference measurement using each calibration file.
[86]:
# This calibration
this_calibration_spectrum = (
(reference_counts - dark_counts)
* (calibration_file # The calibration file we just made
/ (integration_time
* collection_area
* wavelength_spread)
)
)
# Ocean View calibration
ov_calibration_spectrum = (
(reference_counts - dark_counts)
* (ocean_view_cal.values # The OceanView calibration
/ (integration_time
* collection_area
* wavelength_spread)
)
)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 3))
reference_counts.plot(ax=ax1, title='Reference spectrum\n(HL-2000-CAL)')
ov_calibration_spectrum.plot(ax=ax2, ls=':', lw=2, label='OceanView calibration')
this_calibration_spectrum.plot(ax=ax2, ls=':', lw=2, label='This calibration')
lamp_file.plot(ax=ax2, x='Wavelength', y='uJ/cm2', kind='scatter', c='k', label='Known output of HL-2000-CAL (CC)')
ax1.set_ylabel('Counts')
ax2.set_ylabel('$\mu$W/cm$^2$/nm')
ax2.set_title('Calibrated reference spectrum\n(HL-2000-CAL)')
plt.legend()
for ax in [ax1, ax2]:
ax.set_xlabel('Wavelength (nm)');
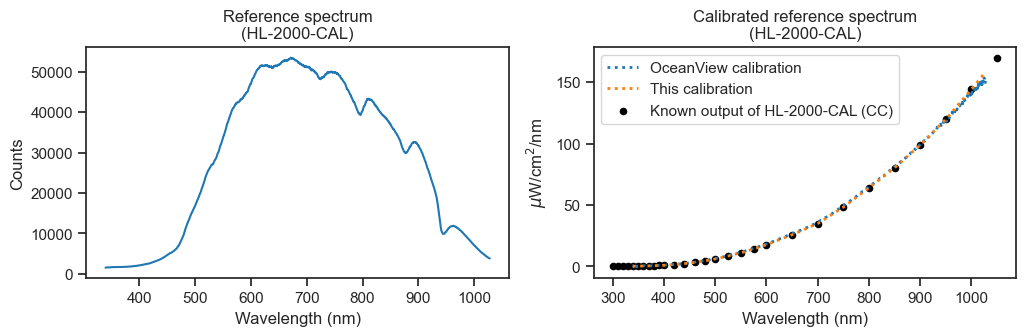
This procedure can be performed immediately before collecting samples. I have updated pyplr.oceanops.OceanOptics so that it can run the irradiance calibration procedure.
Putting it all together¶
[92]:
try:
# Connect to spectrometer
oo = oceanops.OceanOptics.from_serial_number('JAZA1505')
# Obtain sample
counts, info = oo.sample(
correct_dark_counts=True,
correct_nonlinearity=True,
integration_time=None, # Optimize integration time
scans_to_average=3, # Average of three scans
boxcar_width=3, # Boxcar smoothing
sample_id='daylight_spectrum'
)
# Absolute spectral irradiance
irrad_spd = (
(counts) # Already corrected for dark counts
* (calibration_file
/ (info['integration_time'] / 1e6
* collection_area
* wavelength_spread)
)
)
# Visualise
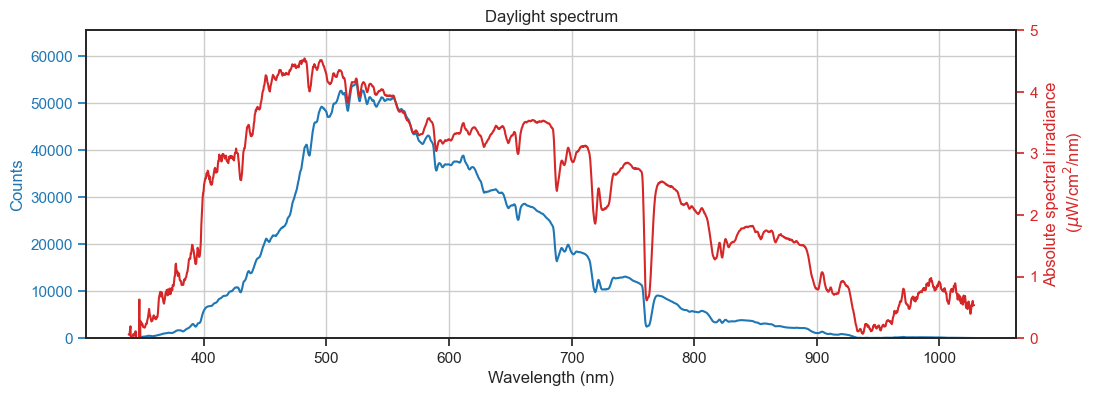
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
ax.plot(calibrated_wls, counts, c='tab:blue', label='Counts')
ax.set_ylabel('Counts')
ax.yaxis.label.set_color('tab:blue')
ax.tick_params(axis='y', colors='tab:blue')
ax.set_title('Daylight spectrum')
ax.set_xlabel('Wavelength (nm)')
ax.set_ylim((0, 65553))
ax.grid()
twinx = ax.twinx()
twinx.plot(calibrated_wls, irrad_spd, c='tab:red', label='Irradiance')
twinx.set_ylabel('Absolute spectral irradiance\n ($\mu$W/cm$^2$/nm)')
twinx.set_ylim((0, 5.))
twinx.yaxis.label.set_color('tab:red')
twinx.tick_params(axis='y', colors='tab:red')
except KeyboardInterrupt:
print('> Measurement terminated by user')
finally:
oo.close()
> Obtaining sample...
> Correcting for dark counts: True
> Correcting for nonlinearity: True
> Integration time: 0.001 seconds
> Maximum reported value: 512
> Integration time: 0.108777 seconds
> Maximum reported value: 42813
> Integration time: 0.141532 seconds
> Maximum reported value: 55145
> Computing average of 3 scans
> Applying boxcar average (boxcar_width = 3)